
Overview#
LLM이 산업계에 본격적으로 사용되기 시작한지도 벌써 몇년이 지났습니다.
Hybrid Cloud의 중요성을 말하며, MSA 구조가 중요하다!라고 말한지 얼마되지 않았는데 이제는 거기에 LLM까지 들어오니 인프라의 중요성이 더욱 부각되는 것 같습니다.
일반적인 Kubernetes의 워크로드와 LLM, 그것도 멀티노드 LLM 추론, 학습은 특히 네트워킹 부분에서 많은 차이점이 있습니다.
이번 포스팅에서는 멀티노드 LLM 추론, 학습을 위한 네트워크 구성중 Infiniband SR-IOV를 활용한 네트워킹을 알아보겠습니다.
MultiNode LLM Workload#
LLM workload는 상당히 복잡하고 많은 레이어를 통해 이뤄집니다.
Training은 수십억개의 데이터를 모으고 정제한 뒤, 토큰화(Tokenization)하고 Transformer를 통해 다음 단어의 확률을 계산하고 예측과 정답의 차이를 구한 뒤, 역전파(Backpropagation)로 각 가중치의 기울기를 계산하여 업데이트합니다. 이 과정을 데이터 전체에 대해 수십-수백번 반복하게 되죠.
Inference는 학습이 완료된 모델의 가중치를 그대로 사용해 새로운 입력에 대한 출력을 생합니다. 수십~수백억 파라미터를 가지고 있어 계산량은 여전히 많습니다.
이렇게 복잡한 계산이 필요한 LLM workload를 최적의 성능을 내게 하려면 어떤 고려사항들이 있어야 할까요?

일반적인 Kubernetes 워크로드가 짧은 request/response로 이뤄지고, 각 pod가 독립적으로 동작하며 패킷을 주고받는 반면에,
LLM Inference에서는 :
- 길고 지속적인 stream
- GPU간 동기화된 Collective Communication(집단 통신) -NCCL(NVIDIA Collective Communications Library)
- GPU의 모든 스레드는 SIMT(Single Instruction Multiple Thread)형태로 처리되며 모든 스레드가 실행되고 다음 Instruction이 실행되는 Lock-Step으로 수행됨
또한 LLM Training/Tuning에서는:
- 매 Step이 All-Reduce 기법으로 이뤄짐 (여러노드에서 계산한 값을 병합하고, 그 결과를 모든 노드에 전달됨)
상기 특징들을 갖고 있습니다.
때문에 수십개의 패킷들이 왔다갔다 할텐데, 하나의 패킷이라도 늦게되면 전체 Step에 영향을 주게 됩니다.
그래서 LLM workload에서는 네트워크의 Latency보다는 Jitter가 더 치명적입니다.
하나의 노드라도 RTT(Rount Trip Time - 패킷의 왕복시간)가 튀게되면 다른 GPU들은 계속 idle상태로 놀게 되는것이죠. 그게 심해지면 NCCL Timeout에 걸려 전체 프로세스가 Fail될수도 있습니다.
Inference에서는 네트워크가 불안정하면 성능이 나빠지는 문제이겠지만,
Training/Tuning에서는 짧게는 몇시간~몇일의 Job이 아예 깨지는 문제가 될 수 있기때문에 네트워크를 주의해서 구성해야합니다.
Latency vs Jitter
Latency: 네트워크내에서 발생하는 지연, 하나의 엔드포인트에서 다른 엔드포인트로 이동하는데 걸리는 시간Jitter: 네트워크에서 데이터 패킷의 전송 지연시간이 변동하는 현상. 패킷이 도착하는 시간이 일관되지 않고 불규칙함
정리하면 Kubernetes에서는 Ingress/Egress(North-South)가 중요하고 Service Mesh와 API중심이었지만,
멀티노드 LLM 워크로드에서는 Pod to Pod. 즉, East-West 통신이 중요합니다.
on Kubernetes(Openshift)#
자 그러면 이제 Kubernetes의 네트워크 구조에 대해서 생각해봅시다.
기본적으로 Kubernetes는 pod들이 물리계층의 네트워크를 직접 관리하지 않고, 추상화된 Overlay 네트워크 계층 위에서 동작합니다.
Overlay네트워크 위에서 동작한다는 의미는… 실제 물리 네트워크의 MTU값과 오버레이 MTU값이 불일치하고, 캡슐화를 위한 헤더가 추가로 붙어 오버헤드를 일으킬 수 있다는 뜻이며… 즉 Jitter를 일으킬 확률이 높아진다는 뜻입니다.
그래서 Kubernetes의 Pod들은 서로 Ip로 통신하며 Underlying network에 대해서는 신경쓰지 않아도 되었지만,
MultiNode LLM workload의 경우엔 NIC종류, Switch Topology, RDMA capability 등 세부적인 네트워크 제어가 필요합니다.
SR-IOV#
SR-IOV(Single Root I/O Virtualization)는 NIC 하드웨어의 Queue/Offload/DMA를 이용해 패킷 전송 경로에서 소프트웨어 레이어를 최소화하기 때문에 Latency나 Overhead, Jitter등을 크게 줄여줄 수 있습니다.
따라서 LLM서빙처럼 네트워크 지연과 일관된 처리량이 중요한 경우에는 SR-IOV를 활성화하는 옵션을 생각해볼 수 있습니다.
Infiniband#
Infiniband는 HPC환경에서 고속, 저지연 상호 연결을 위해 설계된 네트워크 상호 연결 기술입니다.
최신 버전은 최대 400Gbps의 속도를 지원하기때문에 고속네트워크를 필요로 하는 MultiNode LLM workload에는 필수라고 할 수 있겠습니다.
그러나 Infiniband는 Mellanox를 NVIDIA가 인수하면서 경쟁이 사라진 독점기술이고 고가의 가격때문에 쉽사리 도입하기 쉽진 않습니다.
그리고 예전에는 Ethernet보다 Infiniband가 월등하게 성능이 좋았기 때문에 장점이 있었지만, 요새는 Ethernet의 대역폭도 Infiniband 못지않게 올랐기 때문에 굳이 고가의, 벤더종속성이 심한 Infiniband를 왜 사용하냐는 말들도 나오고 있기도 합니다.
RDMA(Remote Direct Memory Access)#
그럼 이제 Infiniband를 분산컴퓨팅의 강자로 만들게 한 RDMA라는 기술에 대해서 알아보도록 하겠습니다.
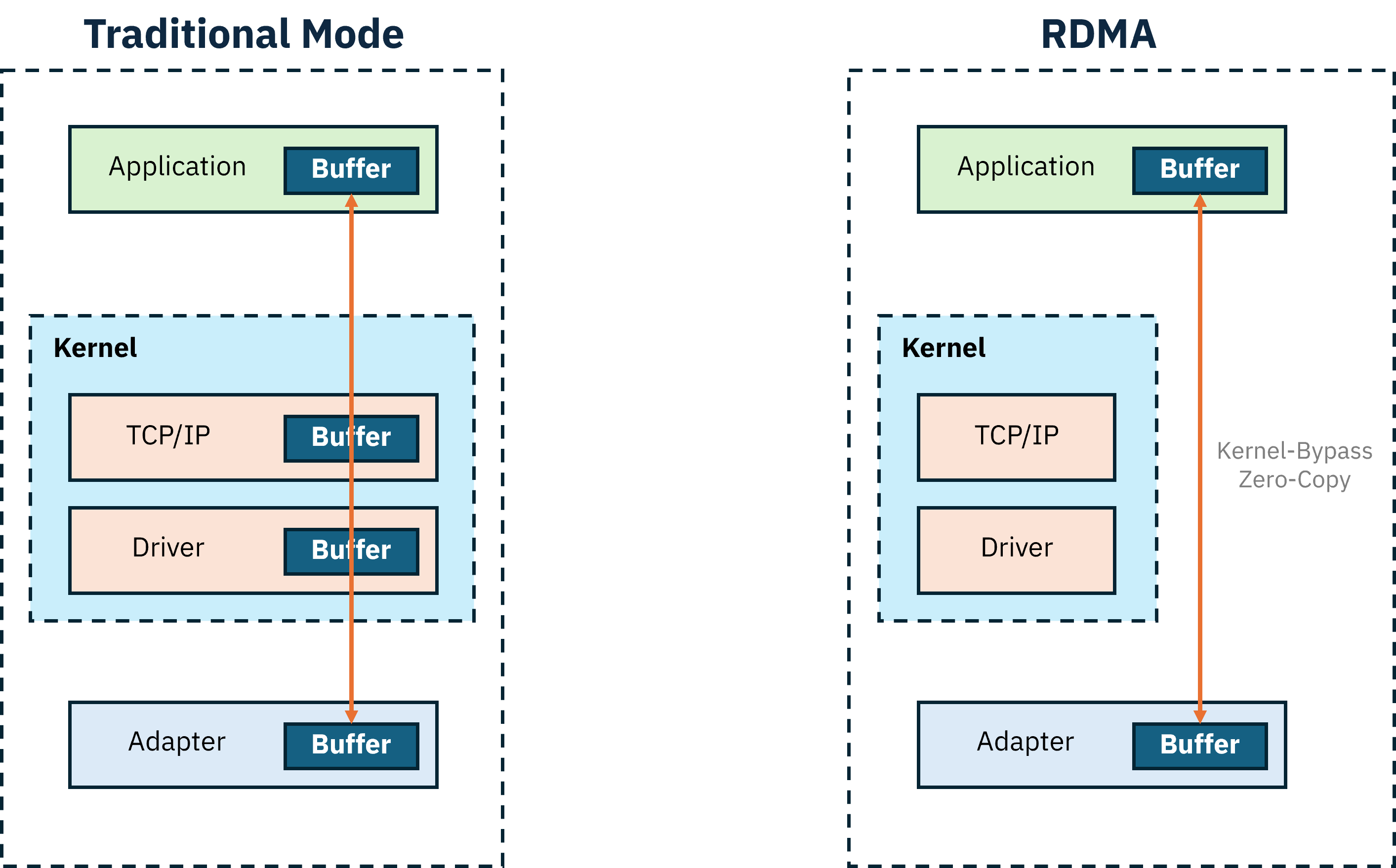
RDMA(Remote Direct Memory Access) 는 OS나 CPU의 개입 없이 한 서버의 메모리에서 다른 서버의 메모리로 데이터를 직접 전송하는 기술입니다.
이는 데이터 복사 과정을 제거하고(zero-copy), 커널영역을 우회하여(Kernel-Bypass) 성능을 극대화시킬 수 있다는 뜻입니다.
위에서 언급했듯이, 이는 MultiNode LLM Workload에서 반드시 필요한 부분이죠!
당연히 수신/송신측의 NIC가 모두 RDMA를 지원해야 가능한 통신기법이긴합니다.
RoCE(RDMA over Converged Ethernet)
RDMA를 Ethernet환경에서도 사용할 수 있게 하는 프로토콜
Infiniband 네트워크 구성하기 - Openshift#
그럼 드디어! Infiniband를 SR-IOV로 Openshift의 서브 네트워크를 구성하여 pod끼리 RDMA통신 실습을 해보겠습니다.
1. Infiniband 장치 확인하기#
서버에 장착된 Infiniband가 제대로 보이는지 확인합니다.
# lspci |grep Infiniband
3c:00.0 Infiniband controller: Mellanox Technologies MT2910 Family [ConnectX-7]
4d:00.0 Infiniband controller: Mellanox Technologies MT2910 Family [ConnectX-7]
5e:00.0 Infiniband controller: Mellanox Technologies MT2910 Family [ConnectX-7]
9c:00.0 Infiniband controller: Mellanox Technologies MT2910 Family [ConnectX-7]
bc:00.0 Infiniband controller: Mellanox Technologies MT2910 Family [ConnectX-7]
dc:00.0 Infiniband controller: Mellanox Technologies MT2910 Family [ConnectX-7]# ip a
10: ibp60s0: <BRODCAST,MULTICAST,UP,LOWER_UP> mtu 4092 qdisc mq state UP group default qlen 256
link/infiniband 00:00:00:6c:fe:80:00:00:00:00:00:00:7c:8c:09:03:00:ae:4c:1c brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff
11: ibp77s0: <BRODCAST,MULTICAST,UP,LOWER_UP> mtu 4092 qdisc mq state UP group default qlen 256
link/infiniband 00:00:00:6c:fe:80:00:00:00:00:00:00:7c:8c:09:03:00:ad:0b:5e brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff
...IPoIB 장치에는 20 바이트 하드웨어 주소가 있습니다.
- 처음 4바이트는 플래그 및 큐 쌍 번호
- 다음 8바이트는 서브넷 prefix(기본 서브넷 prefix는
0xfe:80:00:00:00:00)- 마지막 8바이트는 IPoIB 장치에 연결되는 InfiniBand 포트의 GUID
2. Subnet Manager 확인하기#
Infiniband는 반드시 망 내의 IB Fabric을 관리하는 SDN(Software Defined Network) Controller가 필요합니다.
이를 Subnet Manager(SM) 이라고 부르고, 망 내에 새로운 디바이스가 추가되면 LID(고유번호)를 부여하고 장치의 Link Up/Down이나 Failover를 감지하는 역할을 합니다.
Infiniband 망 내에는 최소 1개의 SM이 필요하고, 여러개 실행할 수 있지만 active SM은 하나입니다.
SM의 역할은 IB Switch가 될 수도 있고, 단순 서버가 될 수도 있습니다.
이번 문서에서는 단순 서버에 UFM(Unified Fabric Manager)라는 소프트웨어를 올려서 Fabric전체를 관리하고 모니터링하도록 SM노드를 만들었다는 전제하에 진행하겠습니다.
Infiniband Fabric 망 내 아무 노드에서 SM노드의 정보확인 :
# sminfo
sminfo: sm lid 1 sm guid 0xe89e4903003xxxxx, activity count 6306612 priority 15 state 3 SMINFO_MASTERLID가 1인 장비가 SM인 것을 확인할 수 있습니다.
Infiniband Switch정보 확인:
# ibswitches
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 6 lmc 0
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 5 lmc 0
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 63 lmc 0
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 97 lmc 0
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 42 lmc 0
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 64 lmc 0
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 3 lmc 0
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 7 lmc 0
Switch : 0xfc6a1c0300xxxxxx ports 65 "Quantum-2 Mellanox Technologies" base port 0 lid 4 lmc 0전체 Fabric의 Topology를 확인하려면:
# ibnetdiscover위 명령어를 치면 노드가 속한 Fabric의 전체 연결 구성도를 확인할 수 있습니다.
3. 간단한 통신테스트!#
그럼 이제 Infiniband 장치끼리 잘 통신이 되는지 간단한 테스트를 진행해보겠습니다.
임시 서버 역할을 할 노드에서 :
# ibping -S -C mlx5_4 -P 1-C : ping받아줄 ib 장치이름-P : 포트넘버
클라이언트 역할 노드:
# ibping -C mlx5_2 -P 1 -L 81
...
Pong from test-cluster-3 (Lid 81): time 0.016ms
Pong from test-cluster-3 (Lid 81): time 0.007ms
Pong from test-cluster-3 (Lid 81): time 0.008ms
Pong from test-cluster-3 (Lid 81): time 0.007ms
Pong from test-cluster-3 (Lid 81): time 0.008ms
--- test-cluster-3 (Lid 81) ibping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4045ms
rtt min/avg/max = 0.007/0.009/0.016 ms-C : ping보낼 클라쪽 장치이름-P: 포트넘버-L : destination쪽 ib장치의 lid
장치이름과 lid는
ibv_devices와ibv_devinfo를 참고
4. 필수 Operator 설치#
위에는 Linux에서 Infiniband의 기본 기능들을 확인했다면, 이제부터는 Openshift위에서 Infiniband Pod network를 구성해보도록 하겠습니다.
Openshift 설치 및 기본 구성까지는 다 되어있다는 전제 하에 진행하겠습니다.
테스트 환경:
- Openshift v4.18
- Infiniband붙은 WorkerNode들은 Baremetal임(VM안됨)
먼저 노드의 PCIe장치를 인식하게 하기 위해서 NFD Operator를 설치하고 NodeFeatureDiscovery를 생성해줍니다.(이 포스팅에서는 기본 template으로 진행)
그럼 Daemonset들이 돌면서 Node에 라벨링을 해주는데, 우리가 확인해줘야할 것은 Infiniband가 존재하는 노드에 network-sriov.capable=true라는 라벨이 붙었는지 입니다.
만약 붙지 않았다면, 아래 과정을 진행할 수 없으니 반드시 확인하고 넘어가야 합니다.
확인해볼 것 :
- 장치에 Infiniband가 제대로 보이는지 (
lspci)- BIOS에서 SR-IOV설정이 enable상태인지
label이 정상적으로 붙었다면, SR-IOV Operator를 설치합니다.
5. Pod Network로 사용할 Infiniband 식별하기#
이제 Pod Network로 사용할 Infiniband(이하 ib)를 식별할 차례입니다.
총 6개의 ib가 존재하고 4개는 Fabric1, 2개는 Fabric2 이런식으로 별도의 망으로 분리되어있다고 가정하겠습니다.
우리가 Pod Network로 만들 ib는 fabric1, 총 4개의 ib입니다.
5.1 vendor:device id 식별#
일단 lspci를 통해 vendor와 device id를 확인합니다.
# lspci -nn |grep Infiniband
3c:00.0 Infiniband controller: Mellanox Technologies MT2910 Family [ConnectX-7] [15b3:1021] ...
4d:00.0 Infiniband controller: Mellanox Technologies MT2910 Family [ConnectX-7] [15b3:1021] ...
...위와 비슷한 출력값이 나올텐데 15b3:1021(vendor:device_id)에 해당하는 부분을 저장해둡니다.
5.2 sriovOperatorConfig 생성#
다음으로 SR-IOV Operator에서 sriovOperatorConfig를 default값으로 생성해줍니다.
5.3 Infiniband 식별#
아래 명령어로 ib 인터페이스가 어떤 이름을 갖고 있는지 확인할 수 있습니다.
# ls -al /sys/class/net/ib*/device/infiniband혹은 lshw를 사용할 수 있다면:
# lshw -c network -businfo
BUS info device class Description
===========================================
pci@0000:3c:00.0 ibp60s0 network MT2910 Family [ConnectX-7]
....device이름과 pci주소를 같이 확인할 수 있습니다. 그러나 interface이름은 확인할 수 없죠.
첫번째 명령어로 인터페이스 이름을 확인했다면, 아래 명령어로 한번에 확인할 수 있습니다.
# ls -al /sys/class/net/ib*/device/infiniband/mlx5*/device mlx5*부분에 위에서 확인한 인터페이스 이름 prefix를 넣어주시면 됩니다.
이렇게 하면 pci bus info까지 확인할 수 있습니다.
매핑정보를 아래와 같이 정리해두고 pod Network에 추가할 ib가 어떤녀석인지 확인합니다.
이번 문서에서는 위의 4개만 사용하도록 하겠습니다.
ibp188s0 - mlx5_4 - bc:00
ibp222s0 - mlx5_5 - dc:00
ibp60s0 - mlx5_0 - 3c:00
ibp77s0 - mlx5_1 - 4d:00
ibp156s0 - mlx5_3 - 9c:00
ibp94s0 - mlx5_2 - 5e:006 SriovNetworkNodePolicy 생성#
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: mlx-policy
namespace: openshift-sriov-network-operator
spec:
resourceName: mlx_test # policy이름
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 8 #노드당 vf 개수
nicSelector:
vendor: "15b3"
deviceID: "1021"
rootDevices:
- "0000:3c:00.0"
- "0000:4d:00.0"
- "0000:bc:00.0"
- "0000:dc:00.0"
deviceType: netdevice
isRdma: truenicSelector아래에 위에서 확인했었던 vendor와 deviceID정보를 넣고, rootDevices에 위에서 찾은 ib의 pci주소를 적어줍니다.
이걸 배포하게되면 mcp가 돌면서 조건에 맞는 노드들은 전부 재부팅됩니다.
7 vf확인하기#
mcp가 완료되었다면, 총 4개의 pf와 8개씩 쪼개진 vf가 정상적으로 보이는지 노드에서 확인합니다.
vf안쪼개진상태:
# ip a
...
10: ibp60s0: <BROADCAST, MULTICAST, UP, LOWER_UP> mtu 4092 qdisc mq state UP group default qlen 256
link/infiniband 00:00:09:e8:fe:80:00:00:00:00:00:00:38:25:f3:03:00:90:85:90 brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff
...vf가 정상적으로 쪼개진 상태:
# ip a
...
10: ibp60s0: <BROADCAST, MULTICAST, UP, LOWER_UP> mtu 4092 qdisc mq state UP group default qlen 256
link/infiniband 00:00:09:e8:fe:80:00:00:00:00:00:00:38:25:f3:03:00:90:85:90 brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff
vf 0 link/infiniband 00:00:03:51:fe:80:00:00:00:00:00:00:38:25:f3:03:00:85:1d:ae brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff, spoof checking off, NODE_GUID 59:ca:bb:00:97:92:74:5f, PORT_GUID 59:ca:bb:00:97:92:74:5f, link-state disable, trust off, query_rss off
vf 1 .....정상적으로 vf가 쪼개지지 않았다면, BIOS에서 sriov가 활성화 상태인지 확인해봅시다.
8 sriovIBNetwork 배포하기#
이제 드디어 pod Network를 만들차례입니다!
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovIBNetwork
metadata:
name: sriov-network-ib-test
namespace: openshift-sriov-network-operator
spec:
resourceName: mlx_test
linkState: enable
networkNamespace: test
ipam: |
{
"type": "whereabouts",
"range": "100.100.100.0/1",
"range_start": "100.100.100.101",
"range_end": "100.100.100.212",
"routes": [{
"dst": "0.0.0.0/0"
}],
"gateway": "100.100.100.1"
}ipam에는 ib의 vf가 연결된 pod들이 가질 ip range와 gateway정보를 넣습니다.
4개의 pf를 8개의 vf로 쪼갰으니, 총 32개의 vf를 사용할 수 있겠습니다. 그럼 ip도 최소 32개가 필요하겠죠!
이것까지 배포가 완료되었으면, Infiniband를 SR-IOV로 연결한 Pod Network는 구성 끝입니다!
9. Test pod띄우기#
apiVersion: v1
kind: Pod
metadata:
name: sriov-demo-pod-1
namespace: test
annotations:
k8s.v1.cni.cncf.io/networks: sriov-network-ib-test
spec:
container:
- name: sriov-container
imagePullPolicy: Always
image: {REGISTRY}/nvidia/doca/doca:3.1.0-full-rt-host
command:
- sleep
- inf
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
resources:
requests:
memory: "1Gi"
cpu: "2"
limits:
memory: "1Gi"
cpu: "2"여기서 유의해야할 점은, pod의 기본네트워크(Ethernet)는 그대로 붙어있고, ib를 사용하는 SR-IOV 네트워크가 secondary로 추가 할당된다는 것입니다.
pod를 생성하고 내부에서 ip a를 입력해보시면 확인할 수 있습니다.
간단한 통신 테스트#
1. rping#
테스트 pod를 두개 띄우고, 한쪽은 서버, 다른 한쪽은 클라이언트로 사용.
rping은 IP주소로 RDMA통신이 되는지 확인하는 테스트 도구입니다.
서버 :
# rping -s클라이언트 :
# rping -c -a 100.100.100.101 -C 1 -v -d mlx5_212. ib_write_bw#
ib_write_bw는 RDMA시, 실제로 성능이 제대로 나오는지 RDMA write 방식으로 Bandwidth를 측정하는 성능테스트 도구입니다.
서버:
# ib_write_bw -d mlx5_16 -a --report_gbits
*************************************
*Wating for client to connect... *
*************************************클라이언트 :
# ib_write_bw -d mlx5_21 -a --report_bgits 100.100.100.101
-----------------------------------------------------
RDMA_Write BW Test
Dual-port : OFF Device : mlx5_21
Number of qps : 1 Transport type : IB
Connection type: RC Using SRQ : OFF
PCIe relax order: ON Lock-free : OFF
ibv_wr* API :ON Using DDP : OFF
TX depth: 128
CQ Moderation: 100
CQE Poll Batch : 16
Mtu : 4096[B]
Link type : IB
Max inline data : 0[B]
rdma_cm QPs: OFF
Data ex. method : Ethernet
-------------------------------------------------------
local address : LID 0x8f QPN 0x012b PSN 0x608xxx RKey 0x040xxx VAddr 0x007fbdb5xxxxxx
remote address : LID 0x90 QPN 0x0049 PSN 0x786xxx RKey 0x008xxx VAddr 0x007f001exxxxxx
--------------------------------------------------------
#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]
Conflicting CPU frequency values detected: 3135.245000 != 4000.000000 CPU Frequency is not max.
2 5000 0.064789 0.064266 4.016633
...클라이언트에서 ib_write_bw날린 이후 서버의 로그:
# ib_write_bw -d mlx5_16 -a --report_gbits
*************************************
*Wating for client to connect... *
*************************************
-----------------------------------------------------
RDMA_Write BW Test
Dual-port : OFF Device : mlx5_6
Number of qps : 1 Transport type : IB
Connection type: RC Using SRQ : OFF
PCIe relax order: ON Lock-free : OFF
ibv_wr* API :ON Using DDP : OFF
CQ Moderation: 100
CQE Poll Batch : 16
Mtu : 4096[B]
Link type : IB
Max inline data : 0[B]
rdma_cm QPs: OFF
Data ex. method : Ethernet
-------------------------------------------------------
local address : LID 0x8f QPN 0x012b PSN 0x608xxx RKey 0x040xxx VAddr 0x007fbdb5xxxxxx
remote address : LID 0x90 QPN 0x0049 PSN 0x786xxx RKey 0x008xxx VAddr 0x007f001exxxxxx
--------------------------------------------------------
#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]
8388608 5000 373.98 373.64 0.005568