
Overview#
이번 포스팅에서는 Data Governance란 무엇인지, Data governance를 실현하기 위해 필요한 몇가지 개념에 대해서 설명해보겠습니다.
Data Governance란?#
요즘 세상엔 데이터가 많아도 너무 많습니다.
부품의 제조년월, 출시일, 유해물질이 있는지 없는지부터 시작해서 어떤 물건이 잘팔리는지, 어떤 성별이 선호도가 높은지 등등…
마케팅을 위해서던지, 산업 동향을 분석하기 위해서라던지 혹은 단순히 저장하던지 각양각색의 이유를 갖고 데이터는 만들어지고 저장되게 됩니다.
데이터의 중요성은 끊임없이 화두되었고, 본격적으로 AI시대가 진행중인 지금에도 여전히 더하면 더했지 덜하진 않아졌습니다.
그럼 도대체 어떻게 데이터를 관리해야 하는 걸까요?
Data Governance는 조직의 데이터를 “자산"으로서 관리하기 위한 철학과 프로세스라고 생각하시면 됩니다.
예를 들면)
- 누가 데이터를 소유하는지
- 누가 데이터 수정이 가능한지
- 데이터 품질은 어떻게 관리되고 있는지
- 데이터에 대한 Policy, Compliance 관리 (ex.
GDPR:General Data Protection Regulation- 데이터 주체의 권리를 보호하는 EU의 법)
즉 조직의 문화, 정책, 관리 철학과 프로세스가 중요합니다.
그러나 데이터의 양과 종류가 많아져, 수천-수백만개의 데이터 자산을 일일히 관리하는 것이 현실적으로는 불가능하기 때문에,
이를 자동화시키고 시스템화 시키는것이 무엇보다 중요해졌습니다.
지금부터는 Data Governance를 실현하기 위한 몇가지 개념에 대해서 설명해보도록 하겠습니다.
1. Governance Framework#
데이터 자체만으로는 그 의미와, 민감도, 소유권등을 알 수 없습니다.
예를 들어서, EMAIL이라는 Column이 있다고 해봅시다. 이게 고객의 이메일인지, 직원의 이메일인지는 데이터만 보고선 알기가 힘들죠.
그래서 필요한 것이 데이터를 설명하는 데이터, Metadata입니다.
그런데 회사마다 사용하는 용어와 Column명이 전부 다를겁니다. 동일한 의미의 데이터를 각 시스템이 서로 다른 이름으로 관리되면 일관된 정책을 적용하기 어렵게 되겠죠.
ex) 고객ID -> customer_id, cust_no, cid등
Governance Framework는 우리 회사의 데이터를 어떤 용어와 규칙으로 설명할 것인가를 정의한 설계도라고 생각하시면 됩니다.
Business Term#
Business Term은 회사에서 사용하는 공통 사전입니다.
예를 들어서 글로벌 리테일 기업의 고객 DB가 있다고 해봅시다.
각 나라별 테이블에 아래와 같은 Column이 있습니다.
미국 : SSN
캐나다 : SIN
인도 : UID
한국 : RRN
Column의 이름은 전부 다르지만 의미는 동일합니다. 개인 식별 번호이죠.
이처럼 기술적인 Column의 이름에 비즈니스적인 의미를 더해주는 것이 Business Term이라고 보시면 됩니다.
위의 예시에서는 개인식별번호라는 Business Term을 만들고 SSN, SIN, UID, RRN등 동일한 의미를 가진 Column을 연결할 수 있겠죠.
Classification#
Classification은 의미보다는 이 데이터가 얼마나 민감한지, 얼마나 보호되어야 하는지를 나타냅니다.
Personal Information, Personally Identifiable Information (PII), Sensitive Personal Information, Confidential 등 여러 보안 등급을 라벨링하여 데이터를 보다 쉽게 컨트롤할 수 있게 됩니다.
Data Class#
Business Term이 데이터의 의미를 나타내고, Classfication이 데이터의 보안 등급을 나타냈다면,Data Class는 데이터의 문법과 패턴을 설명합니다.
예를 들어서 010-xxxx-xxxx라는 패턴은 한국의 휴대전화번호가 될 것이고, xxx@gmail.com xxx@naver.com과 같은 값들은 이메일 주소겠죠.
이처럼 column이름이 아니라 데이터의 실제 값을 보고 어떤 형식인지 판단하는 것이 Data Class입니다.
2. Data Curation#
Data Curation은 데이터를 신뢰할 수 있는 상태로 만들고 쉽게 사용할 수 있도록 조직에 공개하는 과정입니다.
최초의 Data source에는 raw data만 존재하겠죠,
그러나 이 상태로는 이 데이터들이 무엇인지, 품질이 괜찮은건지, 개인정보가 있는지, 믿을 수 있는 데이터인지 모를겁니다.
그래서 metadata를 본격적으로 활용해 데이터의 신뢰도를 높이는 작업을 여기서 하게 됩니다.
Metadata Import & Enrichment#
raw data에서 테이블 명, Column명, 데이터 타입등의 기본 메타데이터를 가져와 비즈니스 의미를 부여하는 단계입니다.
위에서 만들었던 Business Term을 Column에 연결하고, description을 달아, 말 그대로 Metadata를 더욱 풍부하게(Enrich) 만드는 단계입니다.
이 데이터는 무엇을 의미하는가?
Data Profiling#
이제는 실제 존재하는 데이터들을 분석하여 특성을 파악하는 단계입니다.
예를 들어서 Email 컬럼이라면 NULL의 비율이라던가, 길이, 패턴 등을 파악하고,
위에서 만들었던 Data Class도 여기에서 탐지하여 할당해줄 수 있겠죠.
데이터를 이해하는 단계라고 보시면 됩니다.
이 데이터는 어떤 특성을 가지고 있는가?
Data Quality#
위의 Data Profiling단계의 결과 값을 사용하여 데이터의 품질을 파악하는 단계입니다.
예를 들어 Email컬럼에서 xxx@xxx.xxx 과 같은 형식이 아니라 dddd나 zzzz.zz같은 다른 패턴의 값이 많다면 데이터의 품질이 낮아지겠죠.
또한 Null값이나 중복값이 많아도 품질이 좋지 않을 것입니다.
이 데이터를 신뢰할 수 있는가?
Data Lineage#
데이터는 여러 source에 존재합니다.
데이터가 어디에서 생성되어 변환되었고 Asset화 되었는지를 파악하는 단계입니다.
예를 들어 Oracle DB -> ETL -> Iceberg 같은 데이터의 출처를 시각화 하는 단계입니다.
이 데이터는 어디서 왔는가?
Publish#
검증을 끝난 데이터를 권한있는 모두가 볼 수 있는 곳에 게시하는 단계입니다.
curation과정에서 갖게된 메타데이터 정보들을 데이터와 함께 확인 할 수 있고, 쉽게 검색하여 데이터를 찾을 수 있게 됩니다.
이 데이터를 다른 사용자가 사용할 수 있는가?
3. Data Protection#
Data curation을 통해 신뢰할 수 있는 Data Asset을 만들고 조직 내에 공개할 수 있었습니다.
이제는 이 데이터를 누구에게 어떻게 보여줄 것인가를 생각해야겠죠.
Protection Rule#
누가 어떤 데이터를 어떻게 사용할 수 있는지를 정의하는 규칙입니다.
Masking : Column값을 가리거나 변환Row Filtering : 특정 조건에 맞는 Row만 표시Access Control : 데이터의 접근 자체를 허용/거부
위와 같은 기능들은 Business term이나 Classfication, Data Class와 같은 Governance Artifact들을 통해 더 풍부한 조건식을 만들 수 있습니다.
전체 FLOW 요약#
위의 내용을 간략화시킨 flow입니다.
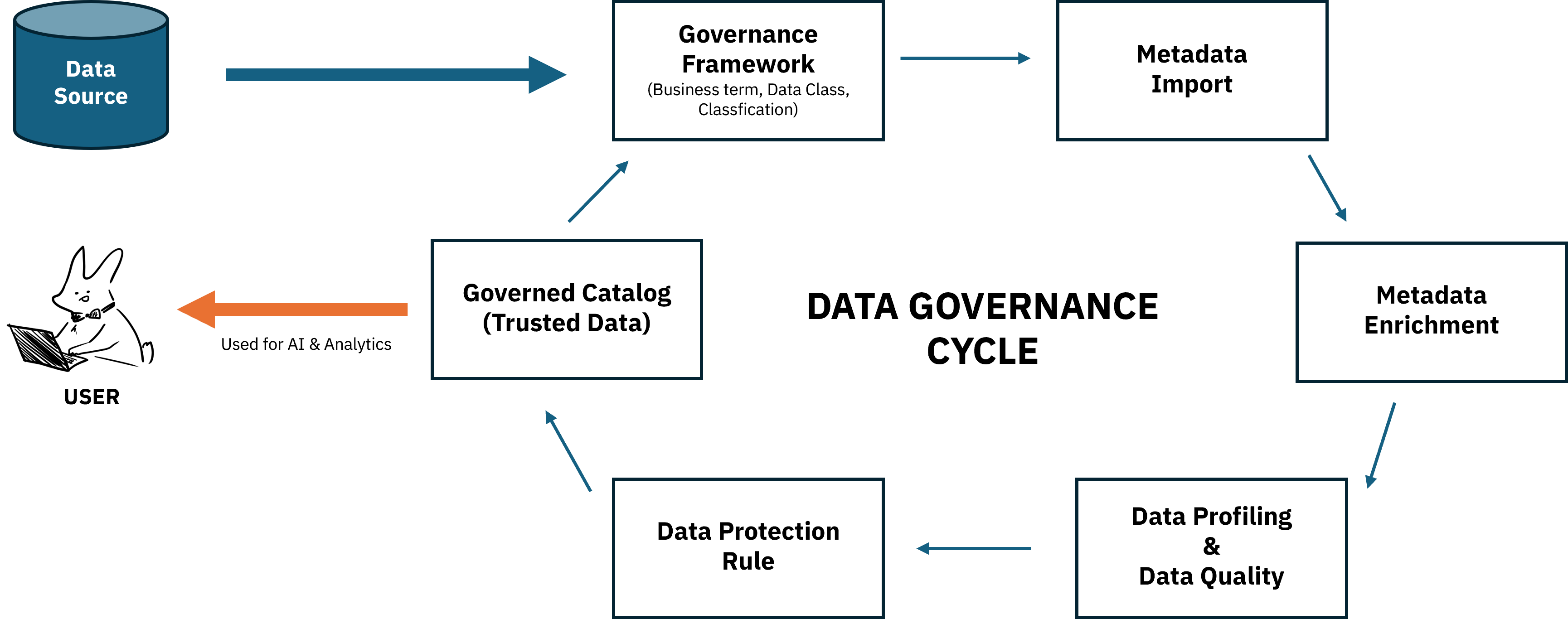
이 프로세스들은 일회성이 아니라 지속적으로 metadata를 보강하고 분석해 신뢰할 수 있는 Asset으로 만들어가는 것이 Data Governance의 핵심이라고 볼 수 있습니다.
