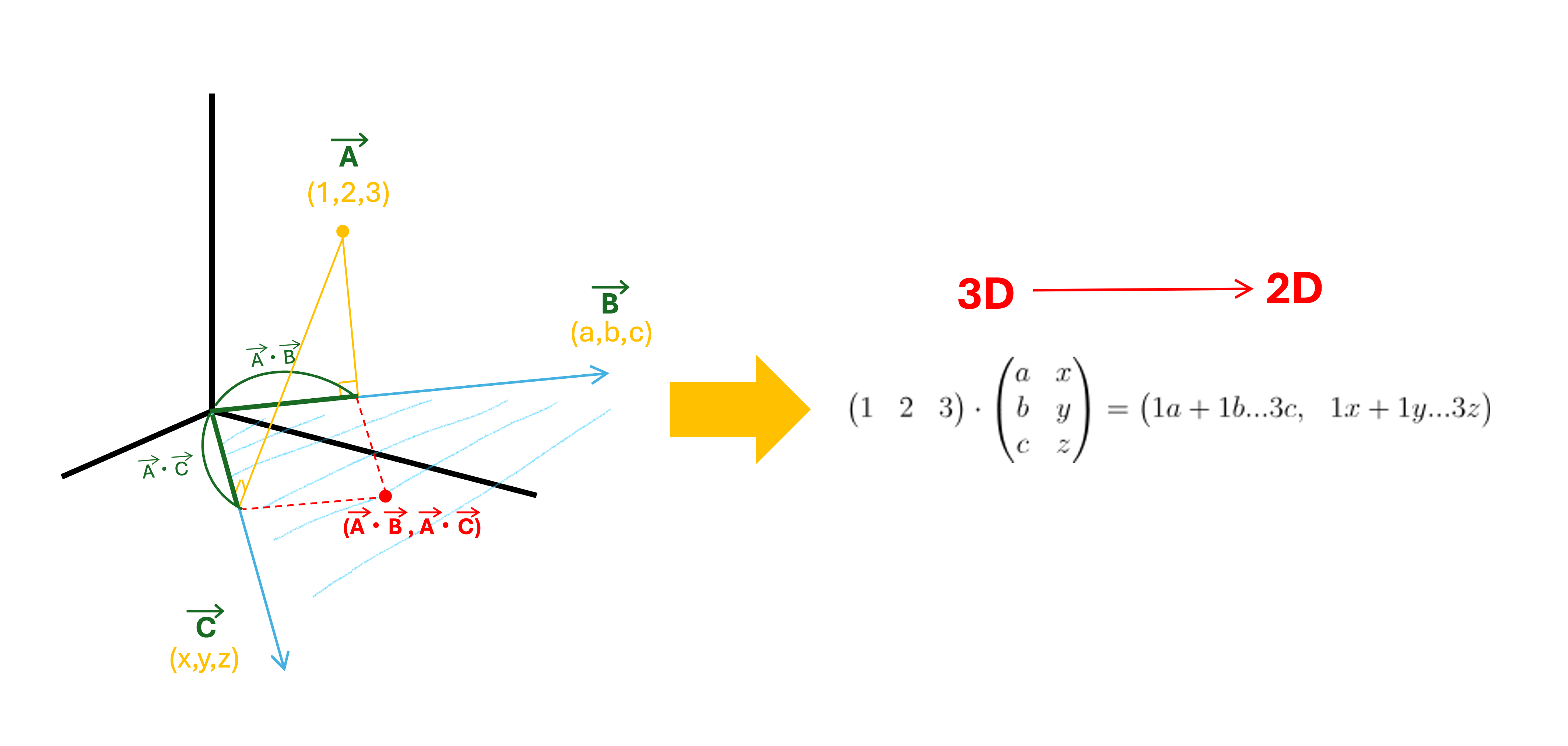
예전에는 One-Hot Encoding이라는 기법을 통해 단어를 숫자벡터로 변환했었습니다.
예를 들어 I like rabbit and I hate coriander 라는 문장을 벡터화한다면 먼저 단어단위로 분해하고(I, like, rabbit, and, I, hate, coriander) { ‘I’ : 1, ’like’ : 2, ‘rabbit’: 3, ‘hate’:4, ‘coriander’:5 }으로 정수를 부여하게 됩니다. 이 과정을 정수 인코딩(Integer Encoding)이라고 합니다.
정수 인코딩(Integer Encoding) 단어를 빈도수 순으로 정렬한 단어집합(vocabulary)을 만들고 빈도수가 높은 순서대로 낮은 숫자부터 정수를 부여
이렇게 정수를 부여하고 나서, 이를 one-hot vector로 나타내면 아래와 같이 표현할 수 있습니다.
I : [1,0,0,0,0] like : [0,1,0,0,0] rabbit : [0,0,1,0,0] hate : [0,0,0,1,0] coriander : [0,0,0,0,1]
이런식으로 간단하게 벡터화를 할 수 있지만, 단어의 개수가 늘어날수록 벡터를 저장하기 위한 공간이 계속 늘어나게 됩니다. 예를 들어 단어가 10000개라면, 각각의 단어는 10000개의 차원을 가진 벡터가 되겠죠! 공간의 활용에 있어서 비효율적이라는 단점이 있습니다.
그리고 이렇게 표현하게 되면 단어의 존재는 쉽게 확인할 수 있지만, 각 단어간 관계성을 파악하기 힘들다는 단점도 존재합니다. 특히 단어간 유사도가 중요한 검색시스템같은 환경에서는 큰 문제가 될 것입니다. (ex. one-hot vector에서 book과 books는 서로 다른 단어로 취급)
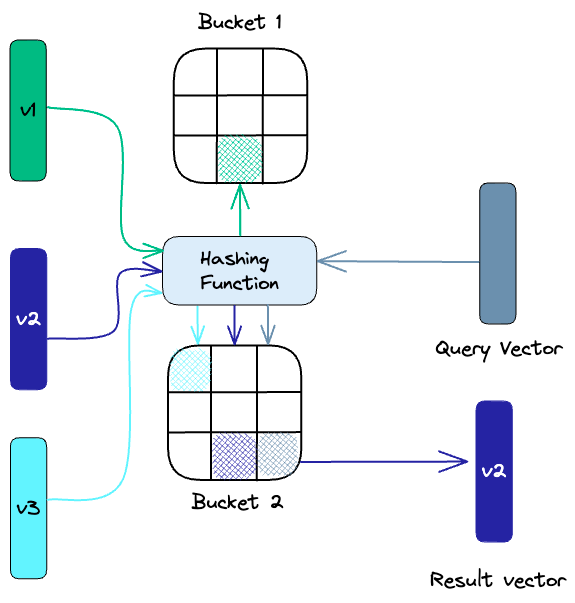
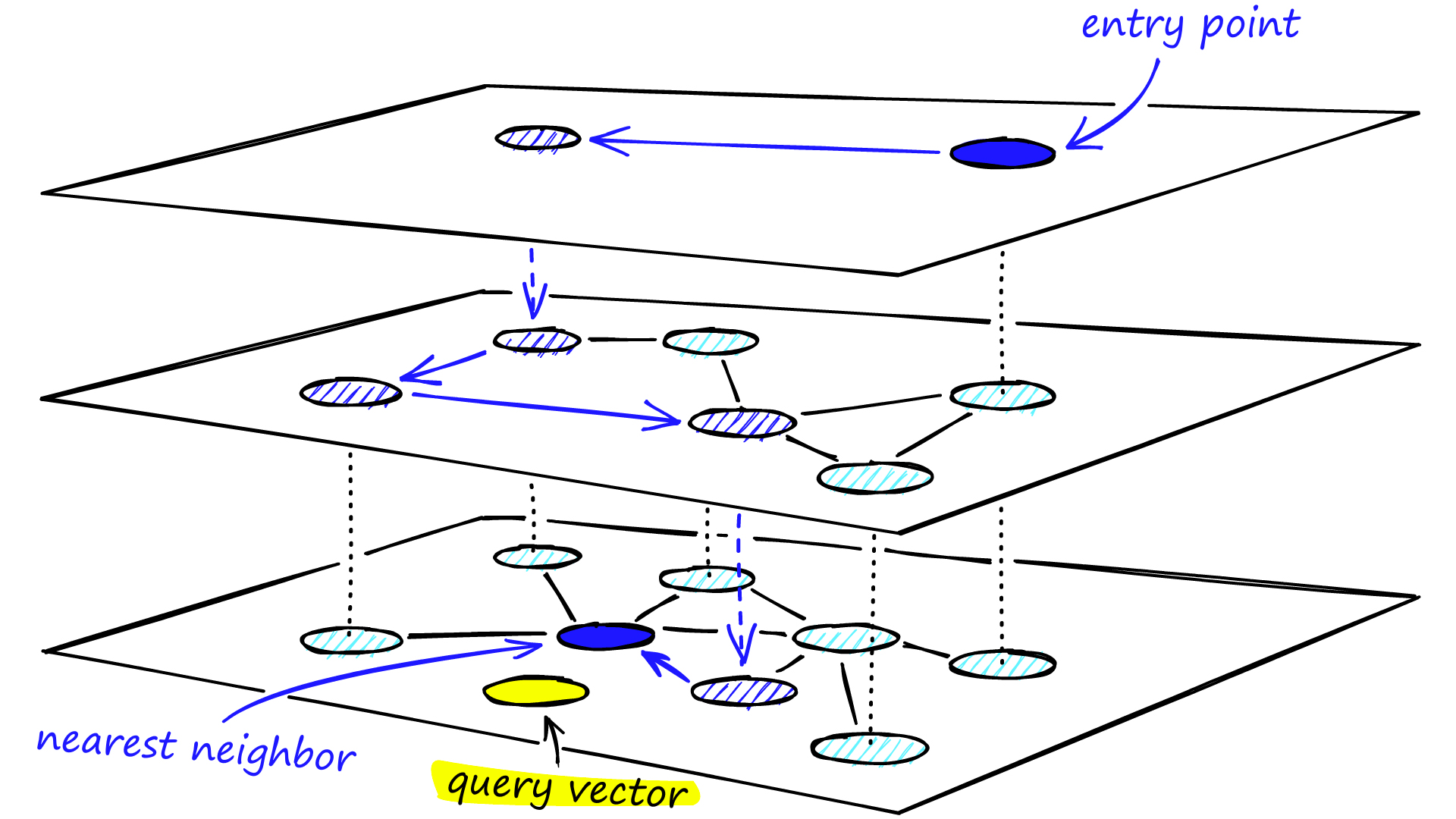
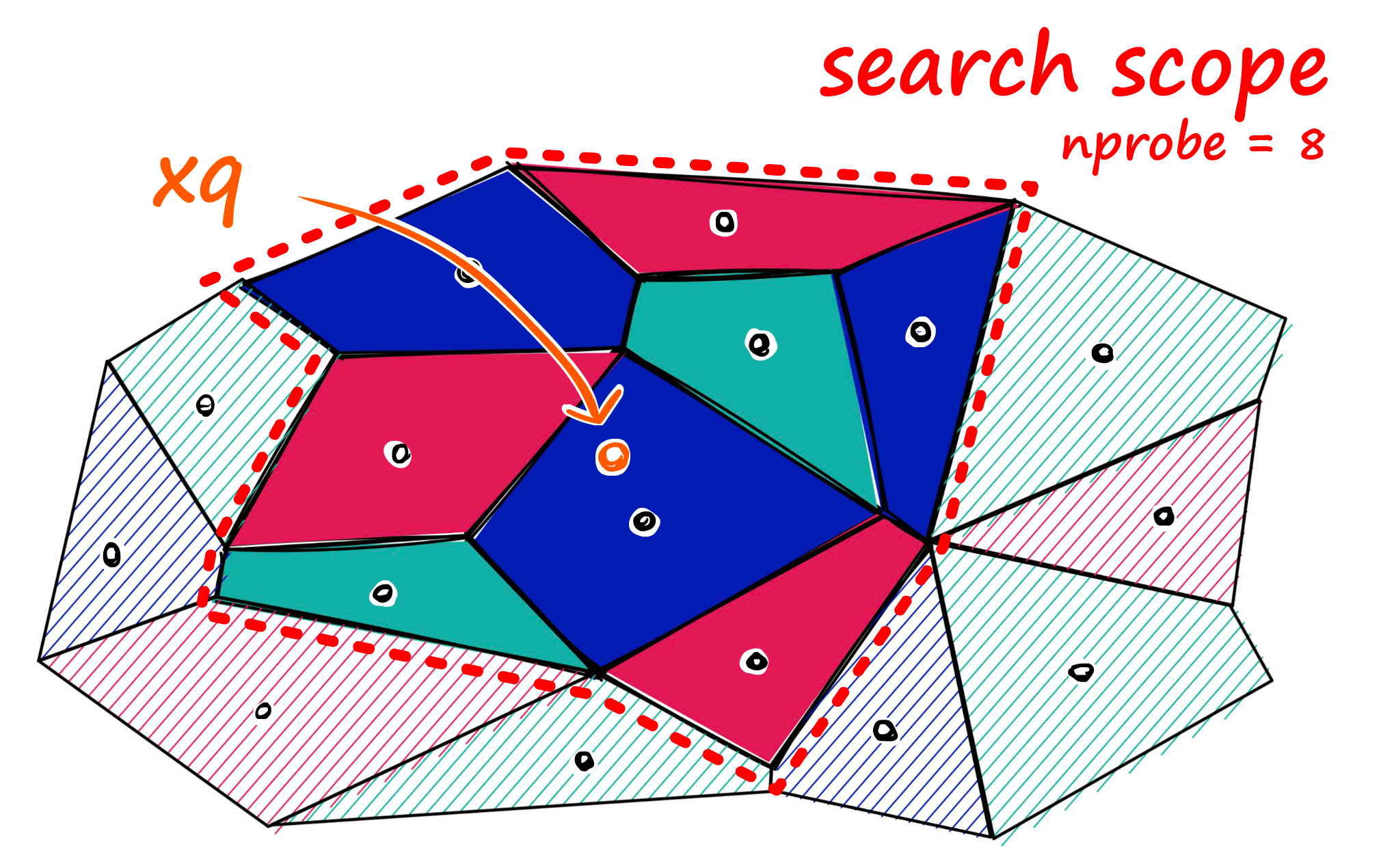
더 빠른 탐색을 가능하게 하는 자료구조로 벡터를 매핑하는 과정입니다. 여러 ANNS(Approximate Nearest Neighbors Search)알고리즘을 활용합니다. 이 알고리즘의 기본 개념은 정확한 결과보다 타겟과 유사한 값들을 검색하는 것이라고 보시면 됩니다.
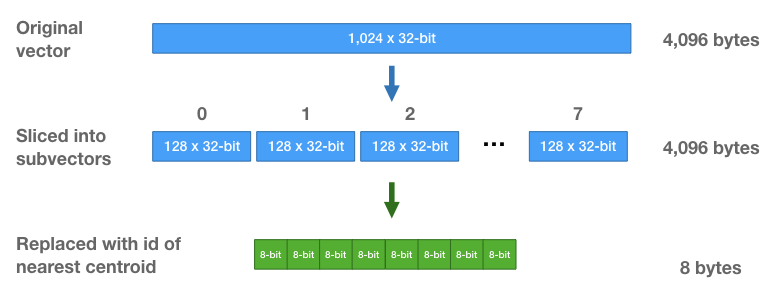
원 벡터를 균등하게 몇 개의 서브 벡터로 쪼개고, 각 서브 벡터들을 Quantization하여 크기를 줄이는 방법입니다.
빠르고 정확도도 좋으며 큰 데이터셋에서 사용하기 좋은 기법이라고 합니다.
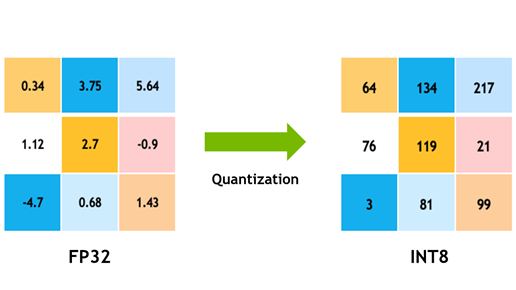
Quantization(양자화)란? 일반적으로 Quantization이란 lower preciision bits로 매핑하는 것을 의미합니다. 예를 들어 우리가 소숫점을 표현할때에는 Float32의 경우, 총 32bit를 사용하고 이를 정수형인 Int8, 총 8bit로 표현한다면 그 경향은 비슷하겠지만 표현할 수 있는 숫자의 범위가 상대적으로 제한될 것입니다. 즉, 값을 표현하는데 사용하는 bit수를 줄임으로써 정확도는 다소 떨어지겠으나, 메모리 사용량을 절감시키고, 계산 소요 시간을 줄일수 있다는 장점이 있습니다.
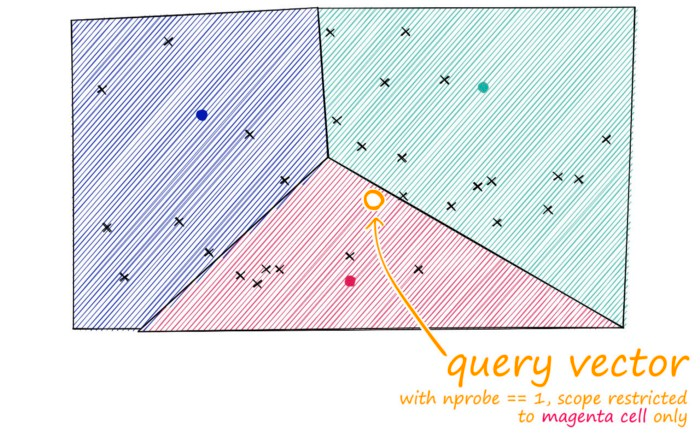
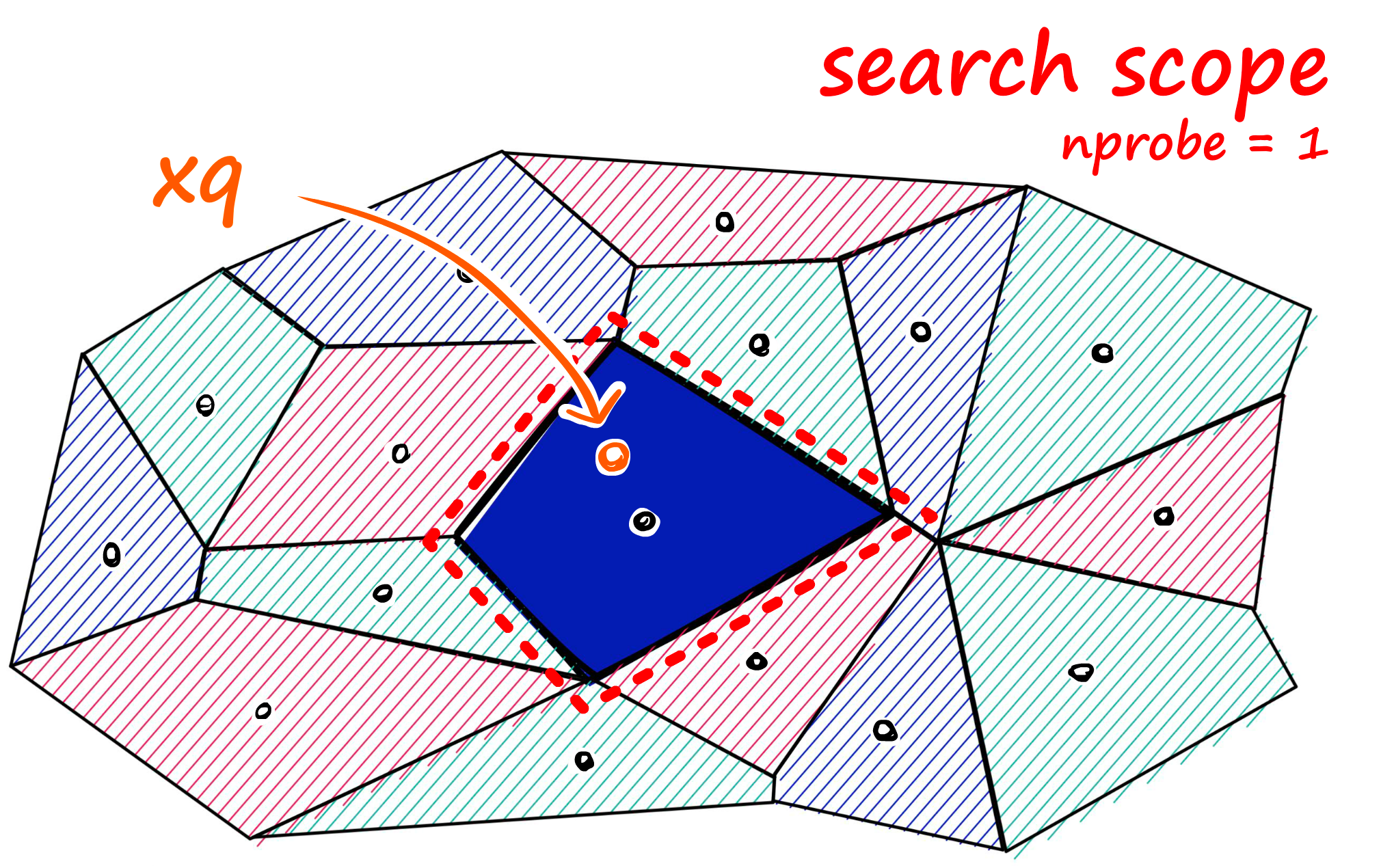
Querying 단계에서는 검색 쿼리가 들어왔을 때, 설정한 Indexing 알고리즘에 따라 유사도 검색을 실행하는데 이 때 유사도 검색을 어떤 방식으로 할것이냐! 를 결정하는 부분입니다.
크게 세가지 방법이 있습니다.
a. Cosine Similarity : 두 벡터간의 각도를 측정, -11사잇값으로 1에 가까울수록 유사한 벡터, -1에 가까울수록 정 반대의 벡터 b. Euclidean distance(L2) : 두 벡터 사이의 직선거리, 0무한대 사잇값으로 0에 가까울수록 유사한 벡터, 값이 커질수록 다른 벡터 c. Dot Product(내적) : 두 벡터 사이의 내적, -∞에서 ∞사잇값으로 양수는 같은 방향, 음수는 반대방향
마지막 Filtering단계에서는 결과값, 혹은 메타데이터의 필터링을 통해 원하는 결과값을 얻어내는 단계입니다.
크게 두가지로 나뉩니다. a. Pre-filtering : Vector Search 이전에 수행, 탐색 공간을 줄이는 장점이 있지만, metadata filter 기준에 맞지 않은 결과는 무시될 수 있고 쿼리 프로세싱을 느리게 만들 수 있음 b. Post-filtering : Vector search 이후에 수행, 모든 결과를 고려해 필터링할 수 있지만, 오버헤드로 쿼리프로세싱을 느리게 만들수있음
대규모 고차원 벡터를 indexing하고 Querying하는데 최적화되도록 설계된 데이터베이스입니다. 그러나 SQL지원이 제한적이고, 데이터의 종류와 형태에 따라 indexing의 파라미터구성을 직접 해줘야 하는데, 이 때 잘못선택하면 검색 결과의 품질이 낮아진다거나 시간이 오래걸리는 등의 비효율성이 발생할 수 있습니다.
Overview # 최근 몇 년 간, 천정부지로 치솟은 GPU제조사 NVIDIA의 주식… 그리고 그래픽카드의 되팔이와 끝도없이 높아진 가격들을 지켜보며
대체 왜? GPU가 어떤 역할을 하기에 코인 채굴이나 AI 연구에 빠질 수 없는 컴포넌트가 된 것일까?? 궁금해했습니다.